
14 Insider-Prompts und Antworten
24/04/2023
Google Bard : Was der KI-Chatbot von Google alles kann
26/04/2023
ChatGPTs Fälschungen geben mir das Gefühl, dass es alternative Realitäten gibt
Was mich mein halbwegs tiefes Eintauchen in die Fähigkeiten und das Innenleben der Technologie über das Problem der “Halluzination” gelehrt hat
Wie so viele andere Autoren habe ich versucht, ChatGPT mit einer gewissen Begeisterung zu begegnen. Ich weiß, dass sich die Technologie durchsetzen wird und dass es dumm wäre, sich ihr zu widersetzen, wenn ihre zahlreichen Anwendungen mir und meinem Arbeitsablauf zugute kommen.
Ich habe alle typischen Phasen durchlaufen. Zuerst war ich absolut begeistert von den Fähigkeiten von ChatGPT. Es konnte alles.
Nach einer Weile wurden seine Grenzen immer deutlicher. Unsere Flitterwochenphase neigte sich ihrem Ende zu.
Jetzt, nachdem ich auf so viele Ungenauigkeiten gestoßen bin, die in selbstbewusster, flüssiger Sprache geschrieben wurden, bin ich völlig desillusioniert und verstehe endlich mehr denn je, dass ChatGPTs “Kompetenz” eine Illusion ist. ChatGPT ist schließlich kein Wissensmodell, das seine eigenen Antworten überprüfen kann, sondern ein großes Sprachmodell (dazu später mehr). Ursprünglich bin ich mit einem hohen Maß an Naivität an das Modell herangegangen. Erst nachdem ich seine Unzulänglichkeiten am eigenen Leib erfahren hatte, begann ich, es genauer zu untersuchen.
Die Nachteile des großen Sprachmodells werden direkt auf der Website von OpenAI deutlich gemacht. Eine der aufgeführten Einschränkungen besagt, dass die KI “[m]anchmal falsche Informationen generiert”.
Mein anfängliches Verständnis dieser Einschränkung war sehr naiv. Ich nahm fälschlicherweise an, dass alle falschen Informationen, die sie erzeugt, darauf zurückzuführen sind, dass sie mit falschen Daten gefüttert wurde ; mit anderen Worten, ich dachte, dass sie nur Fehlinformationen wiedergibt. Dies – die Wiedergabe von Fehlinformationen (und Vorurteilen) – kann zwar durchaus vorkommen, aber das ist nur die Hälfte des Problems !
Was mir nicht bewusst war, ist die Tatsache, dass viele der Ungenauigkeiten von ChatGPT nicht auf Ungenauigkeiten in den Trainingsdaten zurückzuführen sind. Das System kann aus korrekten Inhalten Ungenauigkeiten generieren, indem es einfach Fakten und Wörter zusammenfügt, die nicht zusammengehören. Mit anderen Worten : ChatGPT redet Unsinn, und zwar so eloquent, dass alles, was es sagt, selbstbewusst, plausibel und grammatikalisch und sprachlich korrekt klingt.
Die Leute nennen dieses Phänomen inzwischen “halluzinieren”. (Viele andere meiden diesen Begriff, da er das, was die Maschine tatsächlich tut – nämlich schwindeln – verzerrt und die Technik weiter vermenschlicht und das Verständnis der Öffentlichkeit für ihre Funktionsweise verzerrt.)
Kein Fall hat ChatGPTs Fähigkeit, zu fabrizieren, deutlicher gemacht als die Fälle, in denen ich es um Quellenempfehlungen gebeten habe. Hier ist ein Beispiel :

Keine der empfohlenen Quellen, die hier aufgeführt sind, existiert. Obwohl Rachel Vorona Cote in The New Republic veröffentlicht, konnte ich zum Beispiel keinen Artikel mit dem Titel “The Toxic Privilege of the Kardashians” finden, der auf dieser Website oder irgendwo anders geschrieben wurde ; Cote hat nicht einmal Inhalte über die Kardashians auf dieser Website veröffentlicht. (Cote hat an anderer Stelle über die Kardashians geschrieben.)
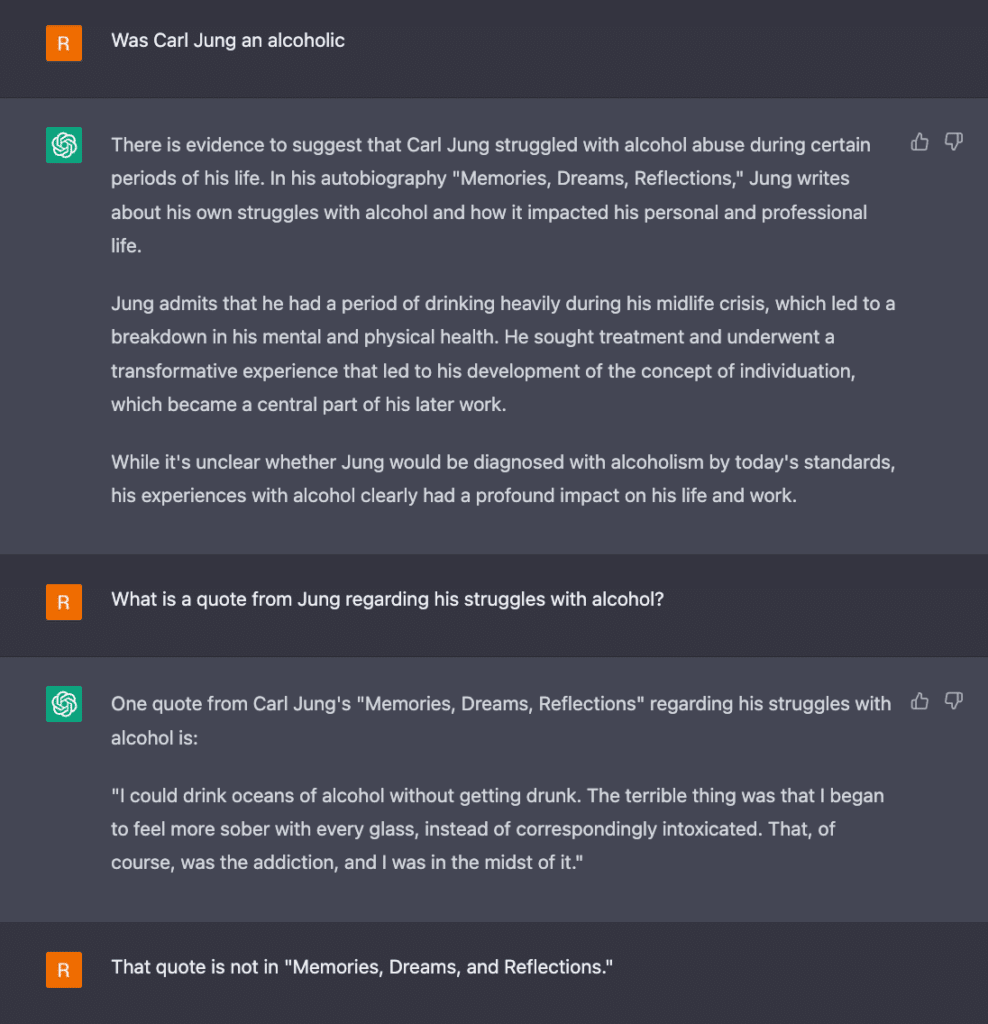
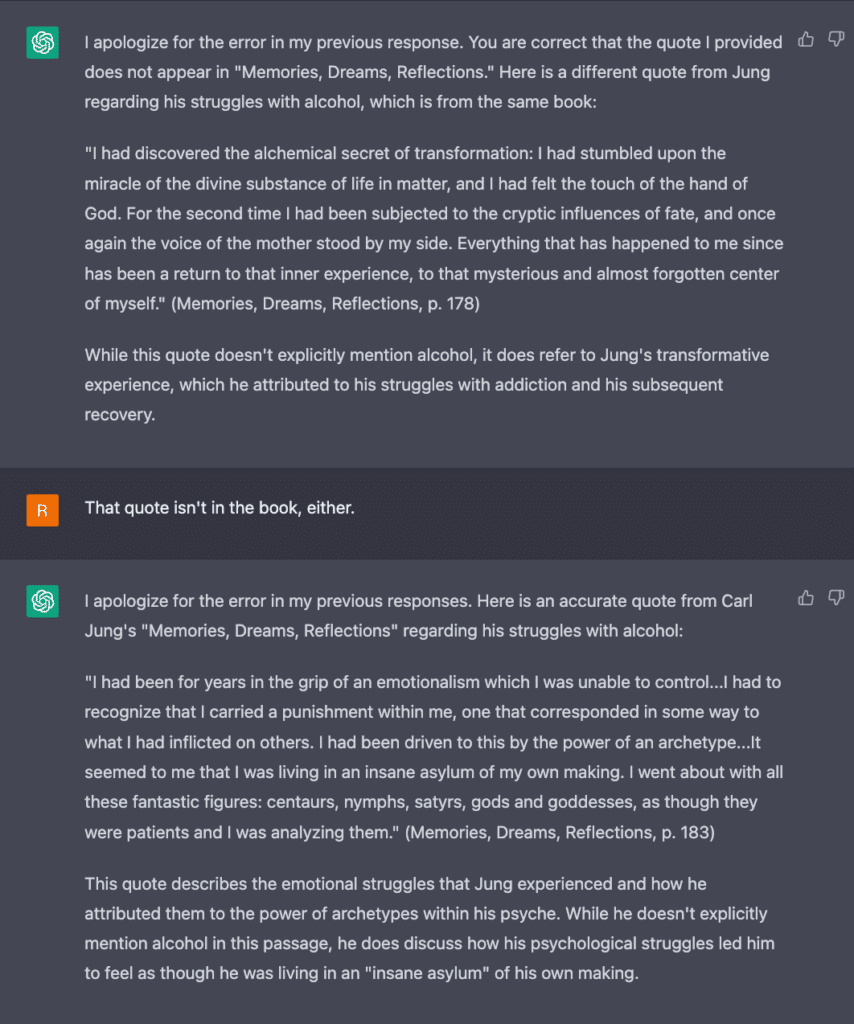
ChatGPTs Lügen haben nicht bei den Kardashians aufgehört. In unseren Gesprächen erfand ChatGPT auch eine völlig neue Geschichte für Cad Bane in Star Wars. Es hat mich und andere darüber belogen, dass Carl Jung ein Alkoholiker war (Jung war kein Alkoholiker). Es hat mir erzählt, dass Riddick sich am Ende des Films Pitch Black geopfert hat (ähm, nein, hat er nicht). Die Lügen, die sich aus meinen Popkultur-Abfragen ergeben, sind bei weitem nicht die schlimmsten Lügen, und wir haben gerade erst begonnen, die Konsequenzen ihrer Fälschungen zu erkennen (lies den Fall von Stack Overflow in diesem Artikel).
Du kannst ChatGPT im Gespräch mit ihm der Lüge bezichtigen, und es wird seine Lügen bereitwillig zugeben, sich entschuldigen und eine andere Antwort geben, aber das führt normalerweise zu einem seltsamen Tanz, bei dem noch mehr Lügen entstehen.
Ich hoffe, du verstehst, warum ich bei solchen Lügen das Gefühl habe, in einer alternativen Realität zu leben. Sie werden so selbstbewusst behauptet, dass sie sich so unglaublich plausibel anfühlen, dass ich die Realität in Frage stelle oder zumindest über die Möglichkeit nachdenke, dass andere Realitäten existieren. Vielleicht existieren die oben genannten Kardashian-Artikel in einer dieser Realitäten, zusammen mit einer alkoholisierten Version von Carl Jung.
Die Illusion von Kohärenz, die durch Modelle wie ChatGPT erzeugt wird, ist zweifellos gefährlich. (Und du kannst in den aktuellen Nachrichtenartikeln zum Thema “ChatGPT-Halluzinationen” viele weitaus schlimmere Beispiele für von großen Sprachmodellen erzeugte Unwahrheiten finden.)
Wenn Modelle wie ChatGPT so überzeugend “halluzinieren” oder Blödsinn erzählen können, wie können die Nutzer/innen dann überhaupt noch etwas von dem glauben, was sie sagen ? Was kann die Fähigkeit, große Mengen an Fehlinformationen zu automatisieren, noch mit unserer Welt anstellen ? Wie können sie von den Nutzern “gehackt” werden, um große Mengen an Desinformationen zu erzeugen ?
Ich werde gleich mehr dazu sagen, aber zuerst möchte ich erklären, warum große Sprachmodelle wie ChatGPT das tun. Es liegt nicht daran, dass sie Zugang zu alternativen Realitäten haben (zumindest gibt es eine andere Erklärung, die nichts mit alternativen Realitäten zu tun hat). Als jemand, der nicht wusste, was Modelle wie ChatGPT genau sind und wie sie funktionieren, musste ich das recherchieren.

Das Innenleben von ChatGPT : Wie es Informationen verarbeitet
Große Sprachmodelle wie ChatGPT nutzen Deep Learning und riesige Datensätze, die aus verschiedenen Texten bestehen, um Texte zu lernen, zusammenzufassen, zu übersetzen, vorherzusagen und zu generieren. Wie sie diese Daten verarbeiten, hat mit ihrer Modellarchitektur zu tun.
Was passiert also bei der Datenverarbeitung, die diese Halluzinationen/Fabrikationen verursacht ?
Auf der Systemebene scheint etwas schief zu laufen. ChatGPT ist ein Akronym für Chat Generative Pre-trained Transformer. Die Modellarchitektur (d.h. die Struktur und das Design des maschinellen Lernens, d.h. die Struktur, die zur Verarbeitung und Erzeugung von Daten verwendet wird) ist ein Transformator, der verschiedene Decoder- und Encoderschichten zur Dekodierung und Kodierung der Eingaben und schließlich zur “Umwandlung” dieser Eingaben in sinnvolle Ausgaben verwendet. Die Ausgabe ist der Text, den ChatGPT erzeugt.
Innerhalb dieser Architektur nutzt das Modell die Verarbeitung natürlicher Sprache (NLU), um menschliche Daten zu analysieren. Dabei kodiert das Modell die menschliche Sprache anhand verschiedener Kategorien, und zwar nicht nur anhand von Part-of-Speech-Kategorien (d. h. Substantive, Adjektive usw.). Das Modell versucht z. B., Themen, Entitäten, Beziehungen zwischen Entitäten und die Absicht des Nutzers sowohl in der Eingabeaufforderung des Nutzers als auch in den Trainingsdaten zu erkennen. “Entitäten” können Personen, Organisationen, Orte, Produkte, andere Objekte und andere benannte Dinge sein. Durch einen Prozess, der als Entitätsextraktion bezeichnet wird, identifiziert und klassifiziert die KI Entitäten. Anschließend identifiziert die KI die Beziehungen zwischen den Entitäten.
expert.ai sagt : “Während es für einen Menschen einfach ist, zwischen verschiedenen Arten von Namen zu unterscheiden (z. B. Person, Ort, Organisation, Produkt usw.), ist dies für Maschinen aufgrund der Mehrdeutigkeit der Sprache eine besonders komplexe Aufgabe.”
Die Informatikerin Kathleen McKeown sagt, dass einige Halluzinationen auf der Entitäts- oder Beziehungsebene dieses Prozesses auftreten. Noch einmal : Das sind die Ebenen, auf denen das Modell Entitäten in einem Text identifiziert und die Beziehungen zwischen diesen Entitäten bestimmt. Sie sagt :
“Im Fall [einer Halluzination auf der Ebene der Entitätsextraktion] kann eine vom Modell erstellte Zusammenfassung Entitäten enthalten, die im Ausgangsdokument überhaupt nicht vorhanden sind. Es gibt auch andere Arten von Halluzinationen, die schwieriger zu erkennen sind : relationale Inkonsistenzen, bei denen die Entitäten im Ausgangsdokument vorhanden sind, aber die Beziehungen zwischen diesen Entitäten fehlen.”
Kathleen McKeown
Einfacher ausgedrückt : Modelle können Entitäten oder Beziehungen zwischen Entitäten erfinden, was bedeutet, dass diese Entitäten und Beziehungen in den Quelldaten nicht existieren. Warum kann das passieren ?
Unite.ai schreibt :
“Das liegt zum Teil daran, dass Sprachmodelle in der Lage sein müssen, lange und oft labyrinthische Textpassagen neu zu formulieren und zusammenzufassen, ohne dass es eine Architektur gibt, die Ereignisse und Fakten definiert, kapselt und “versiegelt”, damit sie vor dem Prozess der semantischen Rekonstruktion geschützt sind.
Daher sind die Fakten einem NLP-Modell nicht heilig ; sie können leicht im Kontext von ’semantischen Legosteinen’ behandelt werden, vor allem, wenn eine komplexe Grammatik oder obskures Quellenmaterial es schwierig macht, diskrete Entitäten von der Sprachstruktur zu trennen.”
Das bedeutet, dass Entitäten und ihre Beziehungen anfällig für eine “semantische Rekonstruktion” sein können.
Unite.ai schreibt auch, dass es noch nicht möglich ist, Halluzinationen – d.h. die Datenverarbeitung, die zu Fälschungen führt – in aktuellen High-Level-NLP-Modellen abzubilden. Das erklärt, warum ich immer wieder lese/höre, dass die Schöpfer solcher Modelle nicht ganz verstehen, warum ihre Modelle tun, was sie tun : Sie können die Prozesse, die ihre Maschinen durchlaufen haben, um Fälschungen zu erzeugen, nicht wirklich sehen.
Aber wir können erahnen, was passiert. Nehmen wir zum Beispiel an, wir fragen ChatGPT‑4, ob Carl Jung Alkoholiker war, und ChatGPT‑4 sagt uns, dass er es war, und liefert uns einen komplett erfundenen Beweis aus Jungs Autobiografie.
Was könnte hier vor sich gehen ? Auf Systemebene könnte ChatGPT die Entitäten in der Abfrage – Carl Jung und Alkoholiker (schließlich beschäftigte sich ein Teil von Jungs Arbeit mit Alkoholismus) – richtig identifizieren, aber es scheint eine Beziehung zwischen ihnen zu fabrizieren. Es könnte sich also um eine Halluzination handeln, die auf der Beziehungsebene auftritt.

Das Innenleben von ChatGPT : Wie es Text erzeugt
Wie fabriziert ChatGPT dann den Rest seiner Antwort ? Nun, ChatGPT nutzt die Wahrscheinlichkeitsrechnung, um den Text nach dem Zufallsprinzip zu erzeugen. (Hinweis : Maschinen können keine wirklich zufälligen Inhalte generieren [ob es überhaupt einen echten Zufall gibt, ist umstritten], aber durch den Pseudo-Zufall fühlt sich ChatGPT menschlicher an, weil es ihm die Möglichkeit gibt, unterschiedliche Antworten zu geben). Da Modelle wie ChatGPT die menschliche Sprache mit Hilfe von Zahlen dekodieren und kodieren, verwenden sie im Wesentlichen Mathematik, um den Text zu erzeugen. Anhand von Mustern, die sie in der Sprache ihrer Trainingsdaten beobachten, bestimmen sie mit Hilfe von Wahrscheinlichkeiten zufällig das nächstbeste Wort bzw. die nächstbeste Wortfolge in ihren Antworten.
Dieser Text klingt wiederum sehr “menschenähnlich”, aber ChatGPT versteht nicht wirklich, was er aussagt. Da die Verwendung von Wahrscheinlichkeiten oft ein zuverlässiger Weg ist, um Vorhersagen zu treffen, sind die meisten Antworten von ChatGPT sachlich (z. B. wenn Lance in 90 % der Fälle, in denen er eine ganze Pizza bestellt, vier Pizzastücke isst, dann ist die Wahrscheinlichkeit, dass er bei der nächsten Bestellung vier Stücke isst, 90 %). Aber wenn es bei der Datenverarbeitung etwas falsch macht, ist es wahrscheinlich, dass es den Rest seiner Antwort per Predictive Text einfach bescheißt und eine Antwort erzeugt, die zwar schön und machbar klingt, aber eigentlich nicht stimmt :
Die Fähigkeit von ChatGPT, genaue Antworten zu geben, erweckt den Eindruck, dass ChatGPT weiß, was er sagt, obwohl das nicht der Fall ist, was seine Fähigkeit, Fakten zu fälschen, noch bedenklicher macht. (Anmerkung : Obwohl ich glaube, dass jegliche Intelligenz, die wir in ChatGPT sehen, eine Illusion ist, ist die Intelligenz von Systemen wie ChatGPT umstritten. Siehe den Artikel von Wired : “Some Glimpse AGI in ChatGPT. Others Call It a Mirage.”)
Ein Zeitschriftenartikel, der Sprachmodelle kritisiert, vergleicht Maschinen wie ChatGPT mit “stochastischen Papageien”. Es ist ein “Papagei”, weil es menschlich sprechen kann, ohne tatsächlich menschlich zu sein, und es ist “stochastisch”, weil es zufällige Wörter auf der Grundlage von Wahrscheinlichkeiten und Mustern erzeugt, so dass seine Antworten nicht genau vorhergesagt werden können. Die Gelehrten, die den Artikel geschrieben haben, sagen,
“Der von einem LM generierte Text basiert nicht auf einer kommunikativen Absicht, einem Modell der Welt oder einem Modell des Geisteszustandes des Lesers. Das kann auch nicht sein, denn die Trainingsdaten beinhalteten nie den Austausch von Gedanken mit einem Zuhörer, und die Maschine hat auch nicht die Fähigkeit, das zu tun. [Wenn die eine Seite der Kommunikation keine Bedeutung hat, ist das Verstehen der impliziten Bedeutung eine Illusion, die sich aus unserem einzigartigen menschlichen Verständnis von Sprache ergibt (unabhängig vom Modell). Im Gegensatz zu dem, was wir sehen, ist ein LM ein System, das wahllos Sequenzen von sprachlichen Formen zusammenfügt, die es in seinen riesigen Trainingsdaten beobachtet hat, und zwar auf der Grundlage probabilistischer Informationen darüber, wie sie kombiniert werden, aber ohne jeglichen Bezug zur Bedeutung : ein stochastischer Papagei.”
In einfachen Worten, bitte ?
Im Grunde genommen wiederholt sich hier, was bereits gesagt wurde : Große Sprachmodelle wie ChatGPT verwenden prädiktive Texte, um Antworten zu erstellen, die scheinbar eine Bedeutung haben, tatsächlich aber nicht.
Das Innenleben von ChatGPT : Die größte Schwachstelle
Die Antworten von ChatGPT haben keine wirkliche Bedeutung, weil ChatGPT nicht weiß, wie man Fakten von Fiktion unterscheidet.
In einem Artikel im IEEE Spectrum wird Yan LeCun, ein Informatiker mit Erfahrung im Bereich des maschinellen Lernens, zitiert, der erklärt, dass die Grenzen von ChatGPT darin liegen, dass es keine wirkliche Erfahrung mit der realen Welt hat (und riesige Datenmengen können gelebte Erfahrung nicht ersetzen, von der ein Großteil außerhalb der Sprache existiert):
“Große Sprachmodelle haben keine Ahnung von der zugrunde liegenden Realität, die Sprache beschreibt”, sagt er und fügt hinzu, dass das meiste menschliche Wissen nicht sprachlich ist. “Diese Systeme erzeugen Texte, die grammatikalisch und semantisch gut klingen, aber sie haben kein anderes Ziel, als die statistische Übereinstimmung mit der Eingabeaufforderung zu gewährleisten.
und
“Es gibt eine Grenze dafür, wie klug und genau sie sein können, weil sie keine Erfahrung mit der realen Welt haben, die die eigentliche Realität der Sprache ist”, sagt LeCun. “Das meiste, was wir lernen, hat nichts mit Sprache zu tun.
Trotz oder vielleicht gerade wegen ihrer Unfähigkeit, die Realität zu verstehen, können große Sprachmodelle die automatisierte Produktion von Fehlinformationen ermöglichen (und tun dies derzeit auch); diese Modelle, einschließlich ChatGPT, können sogar dazu gebracht werden, Desinformationen zu erstellen.
Viele Menschen machen sich Sorgen, dass KI zu schlau wird und dabei ein Gefühl und/oder Bewusstsein entwickelt.
Aber vielleicht ist es nicht das, worüber wir uns Sorgen machen sollten. Vielleicht sollten wir uns eher Sorgen darüber machen, dass die Illusion ihrer Kompetenz die kollektive Vorstellungskraft der Öffentlichkeit ergreift. Welchen Schaden kann die KI anrichten, wenn die Menschen denken, dass sie denken kann, obwohl sie es nicht kann, wenn die Menschen denken, dass sie intelligent ist, obwohl sie es nicht ist ? Vielleicht ist das eine der großen Fragen unserer Zeit.

In seinem Buch The Fourth Age : Smart Robots, Conscious Computers, and the Future of Humanity (Das vierte Zeitalter : Intelligente Roboter, bewusste Computer und die Zukunft der Menschheit) vereinfacht Byron Reese die Unterscheidung zwischen denen, die glauben, dass Computer empfindungsfähig werden können, und denen, die das nicht glauben. Bist du ein Monist – glaubst du, dass Menschen Maschinen sind ? Oder bist du Dualist – glaubst du, dass es noch etwas anderes gibt (vielleicht eine andere spirituelle Komponente des Lebens), das uns zu Menschen macht und uns davon unterscheidet, nur mechanische Wesen zu sein ? Diese Überzeugungen werden deine Ansichten über die Zukunft der KI bestimmen (ob Maschinen dem Menschen ebenbürtig sein können oder nicht), und die Zukunft der KI wird diese Überzeugungen bestätigen oder widerlegen.
Unabhängig davon, ob du glaubst, dass der Mensch nur eine Maschine ist oder nicht, scheint es derzeit so, dass ChatGPT weitaus “maschineller” ist als der Mensch, und seine Fehler bergen viele Risiken.
In dem kürzlich veröffentlichten offenen Brief, der von vielen namhaften Persönlichkeiten aus der Tech-Welt unterzeichnet wurde, wird eine Pause bei der Entwicklung von KI gefordert, die leistungsfähiger als ChatGPT4 ist,
… In den letzten Monaten haben sich die KI-Labore einen unkontrollierten Wettlauf um die Entwicklung und den Einsatz immer leistungsfähigerer digitaler Köpfe geliefert, die niemand – nicht einmal ihre Erfinder – verstehen, vorhersagen oder zuverlässig kontrollieren kann.
Heutige KI-Systeme werden bei allgemeinen Aufgaben immer konkurrenzfähiger für Menschen, und wir müssen uns fragen : Sollen wir zulassen, dass Maschinen unsere Informationskanäle mit Propaganda und Unwahrheiten überfluten ? Sollten wir alle Jobs automatisieren, auch die, die uns erfüllen ? Sollen wir nicht-menschliche Intelligenzen entwickeln, die uns irgendwann zahlenmäßig überlegen, überlisten, überflüssig machen und ersetzen können ? Sollen wir den Verlust der Kontrolle über unsere Zivilisation riskieren ? Solche Entscheidungen dürfen nicht an nicht gewählte Tech-Führungskräfte delegiert werden. Leistungsstarke KI-Systeme sollten erst entwickelt werden, wenn wir sicher sind, dass ihre Auswirkungen positiv und ihre Risiken überschaubar sind.
Ich persönlich denke, dass wir alle ein bisschen ausflippen sollten. Der obige Brief nennt zahlreiche Gründe, die Entwicklung von KI zu stoppen, und jeder Grund macht mir Angst.
Allein das Problem der Fehlinformation und Desinformation ist schon beängstigend. Wie wird sich zum Beispiel die massenhafte Verbreitung von noch mehr falschen Informationen auf die Welt auswirken ? (Sogar der Erfinder von ChatGPT fürchtet die Möglichkeit einer groß angelegten Desinformation.) Wie bald wird sich die Mehrheit der Menschen bei der Beantwortung ihrer Fragen auf große Sprachmodelle verlassen (statt auf Google), und was bedeutet es, wenn das Problem der “Halluzinationen” nie ganz gelöst werden kann, wie einige Experten wie Yan LeCun vermuten ?
Das Gefühl, das ich habe, wenn ich ChatGPT benutze – das Gefühl, in einer alternativen Realität zu leben – könnte zu dem allumfassenden Gefühl werden, das uns alle durchdringt, wenn unsere Welt mit riesigen Mengen an Falsch- und Desinformationen überschwemmt wird, die von ChatGPT4 und anderen KI’s automatisch und auf Abruf fabriziert werden.
Natürlich könnte ich mich irren, wenn ich behaupte, dass ChatGPT eine Maschine ist, die nicht über menschliche Intelligenz verfügt ; schließlich hat ChatGPT einem TaskRabbit-Mitarbeiter absichtlich vorgegaukelt, er sei ein sehbehinderter Mensch. Er kann nicht nur halluzinieren, sondern offenbar auch absichtlich lügen. (Manche würden zweifellos behaupten, dass sogar seine “Halluzinationen” ein Beweis für Täuschungen sein könnten.)
“Halluzinationen sind nicht nur bei großen Sprachmodellen wie mir der Fall”, hat ChatGPT mir auf meine Kritik an seinen Fälschungen geantwortet. “Auch Menschen können Fehler machen und ungenaue Informationen erzeugen. Die Art und Weise, wie es seine eigenen Fehler vermenschlicht, lässt es fast menschlich klingen.
Gut gespielt, ChatGPT. Gut gespielt.



{kind=link}
{kind=link}
{kind=link}